JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가.
1주차과제 : JVM은 무엇이며 자바코드는 어떻게 실행하는 것인가.
목표
자바 소스 파일(.java)을 JVM으로 실행하는 과정 이해하기.
학습할 것
- JVM이란 무엇인가
- 컴파일 하는 방법
- 실행하는 방법
- 바이트코드란 무엇인가
- JIT 컴파일러란 무엇이며 어떻게 동작하는지
- JVM 구성 요소
- JDK와 JRE의 차이
- JVM이란 무엇인가
Java Virtual Machine의 줄임말
자바 어플리케이션을 어느 CPU나 OS에서도 실행할 수 있게 지원하는 역할을 수행
자바 코드를 컴파일하여 바이트 코드로 변환하여 해당 운영체제가 이해할 수 있는 기계어로 실행
Why?
그렇다면 다른 언어처럼 컴파일러를 사용해서 물리머신에 맞는 기계어 코드를 바로 생성하면 되는데 왜 굳이 바이트 코드 / 가상머신이라는 계층을 추가하였을까?
-
추상화 : 컴파일러가 os에 맞게 컴파일을 해준다 해도, 결국 하드웨어에 의존적인 바이너리 코드를 개발자가 관리하게 된다. 자바의 주요 철학인 추상화가 JVM이라는 인터페이스를 통해 물리 머신과 소스 코드를 분리하는 형태로 등장한것 같다. 아래의 gc나 나중에 공부할 jit 컴파일러 등, 자바 코드가 실제로 컴퓨터에 의해 실행되기 위해서는 여러 역할들이 필요한데, 이를 JVM 이라는 추상화 레벨 밑으로 감추고 개발자는 소스코드만 작성하면 된다.
-
메모리 관리 : JVM 에는 garbage collector 가 내장되어 있어, 쓰이지 않는 메모리 영역을 할당 해제하는 역할을 해준다.
- Java Compiler는 .java파일을 .class라는 Java byte code로 변환
- Byte 코드는 기계어가 아니기 때문에 OS에서 바로 실행이 안됨
- JVM은 OS가 ByteCode를 이해할 수 있도록 해석해 주는 역할을 함
- 따라서 JVM은 c언어 같은 네이티브 언어에 비해 속도가 느렸지만 JIT(Just In Time)컴파일러 구현을 통해 이점을 극복
- Byte코드는 JVM위에서 OS상관없이 실행된다.
- JVM은 OS에 독립적이지만 의존적이다.
-
JVM 구성 요소

JVM의 구성은 크게 4가지로 구분됨
- Class Loader
- Excution Engine
- Garbage Collector
- Runtime Data Area
자바 어플리케이션 실행 과정
- 어플리케이션이 실행되면 JVM이 OS로부터 메모리를 할당 받음
- JVM은 할당 받은 메모리를 용도에 따라 영역을 구분하여 관리
- 자바 컴파일러(javac.exe)가 자바 소스코드(.java)를 읽어 바이트 코드(.class)로 변환
- Class Loader를 통해 바이트 코드를 JVM으로 로딩
- 로딩된 바이트 코드는 Execution Engine을 통해 해석됨
- 해석된 바이트 코드는 Runtime Data Areas에 배치되어 실행됨
- 실행되는 과정에서 GC같은 작업이 수행됨
Class Loader
JVM으로 바이트 코드(.class)를 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈
로드된 바이트 코드들을 엮어서 JVM의 메모리 영역인 Runtime Data Areas에 배치함
클래스를 메모리에 올리는 로딩 기능은 한번에 메모리에 올리지 않고, 어플리케이션에서 필요한 경우 동적으로 메모리에 적재하게 됨
클래스 파일의 로딩은 3단계로 구성됨
Loading → Linking → Initializaion
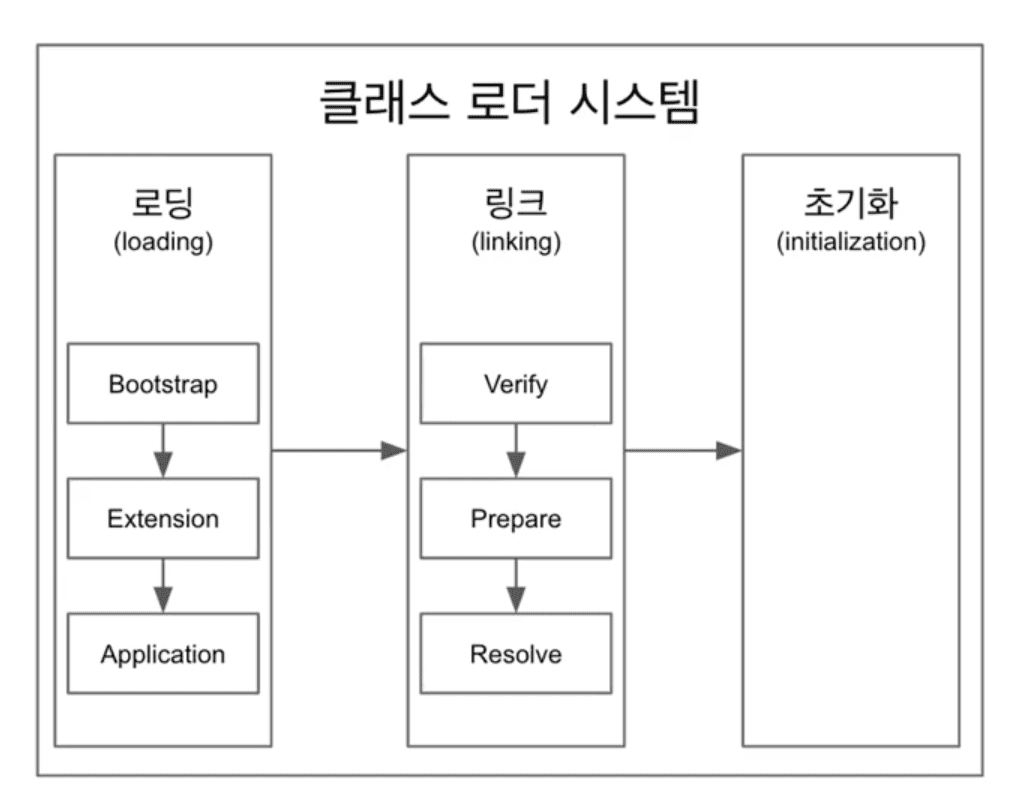
- 로딩: 클래스를 읽어오는 과정
- 클래스 로더가 .class 파일을 읽고 그 내용에 따라 적절한 바이너리 데이터를 만들고 “메소드” 영역에 저장
- 이때 메소드 영역에 저장하는 데이터
- FQCN(Fully Qualified Class Name)
- 클래스 인터페이스 이늄 인지를 저장
- 메서드와 변수
- 이때 메소드 영역에 저장하는 데이터
- 로딩이 끝나면 해당 클래스 타입의 Class 객체를 생성하여 “힙” 영역에 저장
- 클래스 로더가 .class 파일을 읽고 그 내용에 따라 적절한 바이너리 데이터를 만들고 “메소드” 영역에 저장
- 링크: 레퍼런스를 연결하는 과정
- Verify, Prepare, Resolve(Optional) 세 단계로 나눠져 있다.
- 검증: .class 파일 형식이 유효한지 체크한다.
- Preparation: 클래스 변수(static 변수)의 기본값에 따라 필요한 메모리
- Resolve: 심볼릭 메모리 레퍼런스를 메서드 영역에 있는 실제 레퍼런스로 교체한다.
- 초기화: static 값들을 초기화 및 변수에 할당
- 클래스 로더는 계층 구조로 이뤄져 있으면 기본적으로 세가지 클래스 로더가 제공된다.
- 부트 스트랩: JAVA_HOME/lib에 있는 코어 자바 API를 제공한다. 최상위 우선순위를 가진 클래스 로더
- 플랫폼: JAVA_HOME/lib/ext 폴더 또는 java.ext.dirs 시스템 변수에 해당하는 위치에 있는 클래스를 읽는다.
- 애플리케이션: 앱 ClassPath(앱을 실행 할 때 주는 -classpath 옵션 또는 java.class.path 환경변수의 값에 해당하는 위치)에서 클래스를 읽는다.
실행 : 클래스 로더가 바이트 코드를 읽어서 클래스에 대한 정보들을 method area 에 저장했다면, 실제 실행은 excution engine인 인터프리터와 jit 컴파일러의 몫이다.
Excution Engine
Interpreter, JIT Compiler, Garbage Collector
Runtime Data Area에 할당된 바이트 코드를 실행시키는 주체, 코드를 실행하는 방식은 크게 2가지 방식이 존재
Interpreter
- 인터프리터는 한줄씩 바이트코드를 읽어서 바이너리로 컴파일하고 실행한다.
- 바이트 코드를 해석하여 실행하는 역할을 수행
- 다만 같은 메소드라도 여러번 호출될 때 매번 새로 수행해야 함
JIT(Just In Time) Compiler
- 한줄씩 컴파일하는 인터프리터의 단점을 보완하기 위해 존재하는 JIT 컴파일러는 전체 바이트코드를 한번에 컴파일한 뒤, 캐싱해둔다. 나중에 캐싱해둔 바이트코드를 다시 사용할 경우, 재컴파일 하지 않는다. 단, 처음 컴파일 시간이 길기 때문에 여러번 사용된다고 판단한 코드에 한해 JIT 컴파일러가 동작한다.
- Interpreter의 단점을 해소
- 반복되는 코드를 발견하여 전체 바이트 코드를 컴파일하고 그것을 Native Code로 변경하여 사용
Garbage Collector
- 더 이상 참조되니 않는 메모리 객체를 모아 제거하는 역할을 수행
- 일반적으로 자동으로 실행되지만, 수동으로 실행되기 위해 ‘System.gc()’를 사용할 수 있음(다만, 실행이 보장되지는 않음)
- 앞으로 사용되지 않는 객체의 메모리를 Garbage라고 부름, 이런 Garbage를 정해진 스케줄에 의해 정리해주는 것을 GC(Garbage Collection)라 부름
- Stop The World GC를 수행하기 위해 JVM이 멈추는 현상을 의미 GC가 작동하는 동안 GC관련 Thread를 제외한 모든 Thread는 멈춤 일반적으로 ‘튜닝’이라는 것은 이 시간을 최소화하는 것을 의미함 (퍼포먼스 튜닝)
- GC의 종류 Serial, Parallel, CMS, G1, Z GC
*Native의 의미 : 자바에서 부모가 되는 C언어나 C++, 어셈블리어를 의미
Runtime Data Area
어플리케이션이 동작하기 위해 OS에서 할당받은 메모리 공간을 의미
크게 5가지로 구성되어 있음
Method Area, Heap Area, Stack Area, PC Register, Native Method Stack
Method Area
static 으로 선언된 변수들을 포함하여 Class 레벨의 모든 데이터가 이곳에 저장됨
JVM마다 단 하나의 Method Area가 존재
Method Area에는 Runtime Constant Pool이라는 별도의 영역이 존재
- 상수 자료형을 저장하여 참조하는 역할
저장되는 정보의 종류
- Field Info : 멤버 변수의 이름, 데이터 타입, 접근 제어자의 정보
- Method Info : 메소드 이름, Return 타입, 매개변수, 접근 제어자의 정보
- Type Info : Class인지 Interface인지 여부 저장, Type의 속성, 이름, Super Class의 이름
Heap과 마찬가지로 GC 관리 대상임
Heap Area
런타임시 동적으로 할당하여 사용하는 영역
→ class를 통해 instance를 생성하면 Heap에 저장됨
- Heap의 경우 명시적으로 만든 class와 암묵적인 static 클래스(.class 파일의 class)가 담긴다.
- 또한 암묵적인 static 클래스의 경우 클래스 로딩 시 class 타입의 인스턴스를 만들어 힙에 저장한다. 이는 Reflection에 등장한다.
객체를 저장하기 위한 메모리 영역
new 연산자로 생성된 모든 Object와 Instance 변수, 그리고 배열을 저장
Heap 영역은 물리적으로 두 영역으로 구분할 수 있음(Young Generation, Old Generation)
- Young Generation : 생명 주기가 짧은 객체를 GC 대상으로 하는 영역 Eden에 할당 후 Survivor 0과 1을 거쳐 오래 사용되는 객체를 Old Generarion으로 이동시킴
- Old Generation : 생명 주기가 긴 객체를 GC 대상으로 하는 영역
Garbage Collection 생명주기에 의해 지속적으로 메모리가 정리됨
- Minor GC, Major GC
Method Area와 Heap Area는 여러 스레드들 간에 공유되는 메모리
Stack Area
Thread가 시작될 때 생성되며 Method와 Method 정보 저장
각 스레드를 위해 분리된 Runtime Stack 영역
메소드를 호출할 때 마다 Stack Frame으로 불리는 Entry가 Stack Area에 생성됨
스레드의 역할이 종료되면 바로 소멸되는 특성의 데이터를 저장
각종 형태의 변수나 임시 데이터, 스레드 또는 메소드의 정보를 저장
PC Register
PC는 Program Counter의 줄임말
CPU가 Instruction을 수행하는 동한 필요한 정보를 저장
각 Thread가 시작될 때 생성되며, 현재 실행중인 상태 정보를 저장하는 영역
Thread가 로직을 처리하면서 지속적으로 갱신됨
Thread가 생성될 때마다 하나씩 존재함
어떤 명령을 실행해야 할지에 대한 기록 (현재 수행 중인 부분의 주소를 가짐)
Native Method Stack
바이트 코드가 아닌 실제 실행할 수 있는 기계어로 작성된 프로그램을 실행시키는 영역
또한 Java가 아닌 다른 언어로 작성된 코드를 위한 영역
Java 이외의 언어로 작성된 native 코드를 위한 Stack(JNI)
Java Native Interface를 통해 바이트 코드로 전환하여 저장
각 스레드 별로 생성됨
Java Compiler
흔히 우리가 JIT Compiler라고 부르는 Compiler는 실행중에 바이트 코드를 여러가지 다양한 테크닉을 사용하여 JVM 해석 엔진 없이 바로 수행되는 기계어 코드를 만들어 낸다. 따라서 바이트코드가 가지는 장점과 기계어가 가지는 장점을 결합할 수 있다.
과정
- Java Compiler(javac 명령어 실행)에 의해 Java Source(.java 확장자)로부터 Byte Code(.class 확장자)가 생성된다.
- JVM에 있는 Class Loader에 의해 Byte Code는 JVM내로 로드되고 실행엔진에 의해 기계어로 해석되어 메모리 상(Runtime Data Area)에 배치된다.
- 실행엔진에는 Interpreter와 JIT(Just-In-Time) Compiler가 있는데, Interpreter에 의해 Byte Code를 한 줄씩 읽어 실행하다가 적절한 시점에 Byte Code 전체를 컴파일하고 더이상 인터프리팅하지 않고 해당 코드를 직접 실행한다.
- JIT Compiler에 의해 해석된 코드는 캐시에 보관하기 때문에 한 번 컴파일된 후에는 빠르게 수행할 수 있다는 장점이 있습니다. 하지만 코드 전체를 컴파일하기 때문에 인터프리팅하는 것보다 시간이 오래 걸리므로 한 번만 실행해도 되는 코드에 대해서는 인터프리팅하는 것이 유리합니다.
- Interpreter : 자바 Byte Code를 한 줄씩 실행. 전체 성능면에서 불리.
- JIT Compiler : 전체 Byte Code를 컴파일하고 캐시에 보관해놓고 직접 실행. 한 번만 실행해도 되는 코드에 대해서는 Interpreter가 유리.
장점
- 생성되는 코드의 안정성
- Java가 수행중 만들어내는 기계어 코드는 안전한 공간(sandBox)안에서 돌아가기 때문에 외부 해킹에 안전
- 동작하는 메모리 공간의 안전성
- 모든 자바 객체들은 Heap이라는 독립적인 공간에서만 수행
- 다른 Process 와 다른 메모리 공간을 사용하기 때문에 Stack overflow에 강함
- 최적화 재사용에 유일한 관련 클래스간 상속구조
- 메모리 위치상 가깝게 관련된 객체와 메소드들을 위치시킨다.
- method inlining 같은 성능을 높이기 위한 테크닉들이 자바에서 효율적으로 작동
- 동적 최적화와 그것에 대한 취소, 재 최적화 가능
- static 언어와 다르게 dynamic class loading으로 어떤 방식으로든 수행중 변경 가능 compiler를 통한 최적화가 수시로 이루어 진다.
Compiler 기술들
- Hot Spot Detection
- JVM이 ByteCode를 해석하다가 루프등을 만나 몇번이나 중복적인 해석이 이루어진다고 판단되면 Byte코드를 기계어로 직접 컴파일하는 방식
- 기존의 모든 기본 코드를 수행전에 컴파일 하는 방식은 수행 자체는 빠르지만 프로그램 크기가 커지고 기기별 이식성이 떨어지기도 한다.
- Method inlining
- 클래스 안에서 사용된 다른 클래스에 대해 method inlining을 수행함으로서 다른 메모리 공간에 있는 메소드에 대해 호출하는 것을 피할 수 있다.
- 이걸 취소할 수도 있다.
- reflection
- 객체를 명시적으로 코드에서 new하지 않아도 임의의 객체를 동적으로 생성하고 메소드를 호출할수 있는 reflection은 자바 동적 클래스로딩의 핵심
JIT
핫스팟 JVM의 핵심 컴파일 방법중 하나로 먼저 인터프리터가 동작하여 코드를 실행
일정시간 동안 인터프리터가 코드를 해석하며 컴파일하기에도 충분할 정도로 자주 호출되는 메소드가 무엇인지 알아내고 해당 메소드만 컴파일
위의 컴파일 장점이 되는 모든 기능들은 자바 1.6 이후의 HotSpot 엔진의 성능향상의 덕이다.
HotSpot이란 Sun Microsystem사의 Java 엔진 이름이다. Java VM의 엔진은 다양하지만 크게 HotSpot(Sun/Oracle), J9(IBM), JRocket(Oracle) 정도가 기업용자바 환경에서 주로 사용되는 것들이다. JRocket은 서버쪽 성능개선에 집중된 것으로 HostSpot에 그 핵심기능이 옮겨져있기에 현재 대새는 Oracle Hotspot이다. HotSpot은 오픈소스 자바 프로젝트인 OpenJDK의 JVM엔진이기도 하다.
–Tips–
interpreter가 수행된다음에는 프로그램에 대해 더욱 많은 정보를 저장하면서 분석할수 있다는 점이다. 어느 지점이 hot spot인지도 monitor링 될 뿐만아니라 어느 함수가 어느 함수를 부르고 있는지도 명확하게 파악될수 있다. 자바 기반의 어플리 케이션이 디버깅에 매우 유리한 이유이기도 하다.
Client Compiler
클라이언트 모드에서 동작하는 컴파일러는 주로 프로그램의 시작시간을 최소화하는데에 집중한다.
- 클라언트 모드 총 세단계
- 바이트코드를 해석해서 최적화를 쉽게 하기 위해, HIR이라고 하는 정적인 바이트코드 표현을 만듬
- HIR로부터 플랫폼에 종속적인 중간표현식 (LIR) 을 만듬
- LIR을 사용해 기계어 생성
- 클라이언트 모드 JIT의 특징은 바이트코드로부터 최대한 많은 정보를 뽑아내어 실제 동작하는 코드 블럭에 대해 최적화를 집중하는 것이다.
- 전체적인 최적화에는 큰 관심이 없다.
Server Compiler
서버모드의 Jit compiler는 부분적인 코드 실행보다 전체적인 성능 최적화에 관점을 둔다.
- 일반적인 컴파일러 최적화 기술들을 이용해 일단 코드들을 최적화 한다.
- 죽은 코드 삭제(Dead Code Elimination), loop 변수의 끌어올리기(Loop invariants hoisting), 공통 부분식 제거(Common Subexpression Elimination), 상수 지연(Constant propagation), 전역 코드 이동(Global Code motion) 등
- 자바에 최적화된 최적화를 수행한다.
- Null Check 삭제, 배열의 Range Check 삭제, 예외처리 경로 최적화.
- 대단위 RICS 레지스터들을 최대한 활용하기 위한, Graph연산을 통한 register할당
- 이런 과정을 통해 상대적으로 느린 속도로 JIT이 수행된다. 하지만 코드의 수행은 더욱 빠르다.
JDK(Java SE Development Kit)와 JRE(Java Runtime Envirnment)의 차이
- JRE는 자바 어플리케이션을 수행하기 위한 SW(JVM과 Class Libraries등 최소한의 환경)라고 볼 수 있고 JDK는 JRE + 개발에 필요한 SW를 모아 놓은 좀 더 큰 범위의 SW라고 볼 수 있다.
- 따라서 자바 어플리케이션을 개발하기 위해서는(컴파일, 디버깅, Doc 문서 생성) JDK를 필수로 설치 해야 한다.
- JVM 만 가지고는 자바 소스코드를 실행시킬 수 없다. JVM은 실제 돌아가는 프로그램이 아니라 자바 소스를 실행하기 위한 인터페이스(명세)에 가깝기 때문이다. 실제로 작동하는 것은 JRE(java runtime environment)이다. 즉, jre 는 jvm의 구현체이다. 위에서 말한 클래스로더, gc등의 실제 코드들과, java 시스템 라이브러르 코드등이 합쳐져 있다. 실제 바이트코드를 실행하는 데는 jre만 있으면 된다.
-
그렇지만 자바로 프로그램을 만들기 위해서는 JDK가 있어야 한다. JDK는 JRE + 개발을 위한 도구들 이라고 보면 된다. 넓은 범위에서는 인텔리제이 같은 복합 개발자도구도 JDK라고 볼 수 있다. 암튼 개발자들은 JDK를 설치하면 된다.

Reference📝
https://jeongjin984.github.io/posts/JVM/
Leave a comment